Research
情報科学
ことばとコンピュータ

写真は、COVID-19対応のため、研究室からリアルタイムでオンライン授業を行っている様子です。画面を半分に分け、スライドを写しながらホワイトボードアプリに板書する形式で行いました。チャットによる質問が活発になると、授業は楽しいです。
コンピュータを用いて、ことばを解釈する、類推する
データサイエンス領域 原一夫 教授
「私は辛いカレーが好きですが、辛くておいしいカレーを自分では作れません。」
この文を書いた人は、自炊派でしょうか、それとも、外食派でしょうか。おそらく外食派でしょう。なぜなら、自分で作れない料理を求めてレストランに外食に行くだろう、と考えられるからです。逆に、「私は辛いカレーが好きですが、辛くておいしいカレーを食べられるお店が近所にありません。」と書く人は、おそらく自炊派でしょう。
こうしたことばの解釈は、コンピュータでもできます(完璧ではないですが)。http://analogy.sakura.ne.jp/classify/naiveBayes.html
を試してみてください(図1)。どうやっていると思いますか?
「日本の首都は東京ですが、イギリスの首都はどこでしょうか」「ロンドンです」
「青森の特産果物はリンゴですが、山形の特産果物は何でしょうか」「サクランボです」
これらはことばの類推クイズですが、やはり、コンピュータでも正解できます(完璧ではないですが)。http://analogy.sakura.ne.jp/word2vec/quiz.html
を試してみてください(図2)。どうやっていると思いますか?
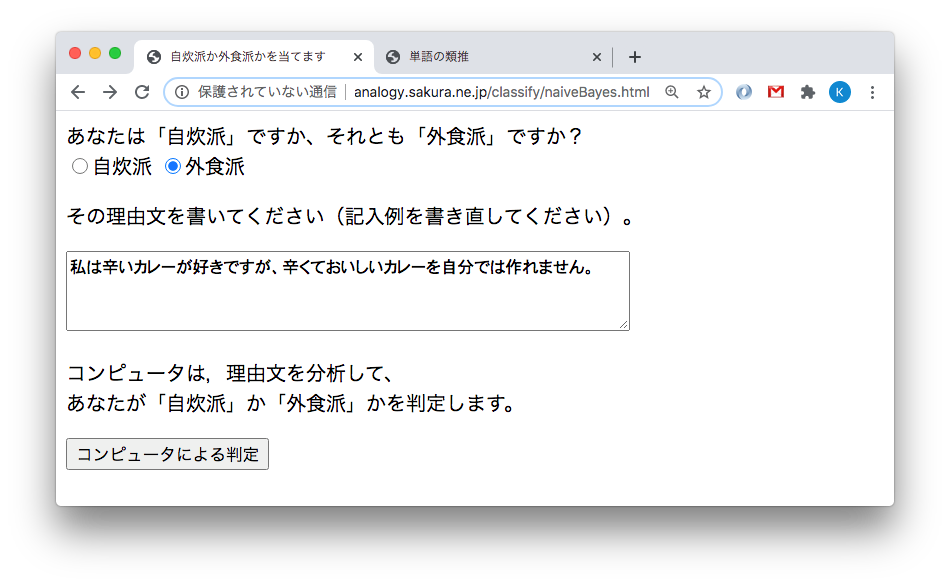
図1: テキストの解釈(分類)
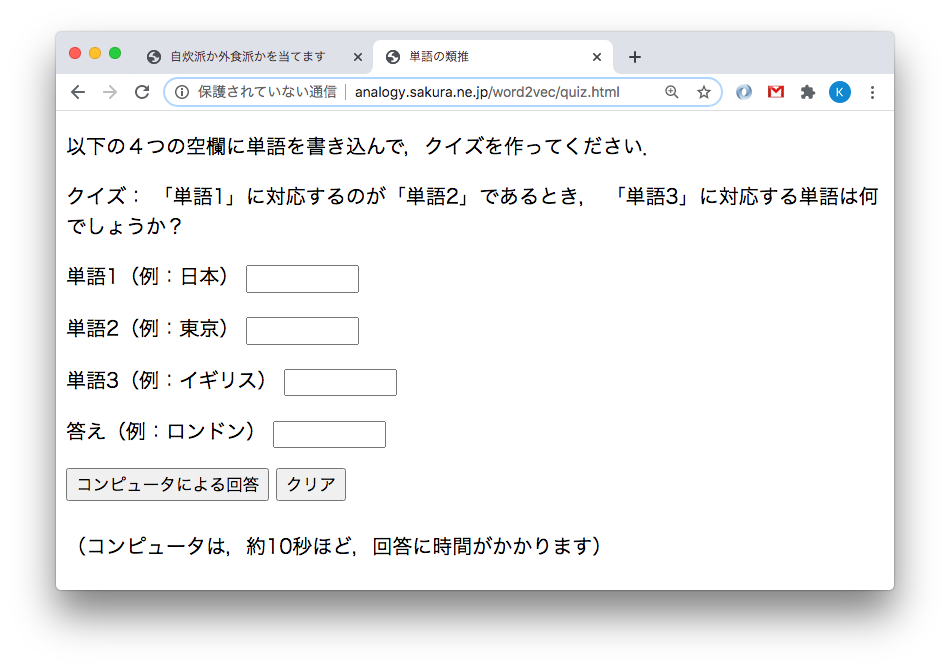
図2: 単語の類推
実は、コンピュータは、蓄積されたデータ集を利用しています。正確さよりもわかりやすさを優先して説明すると、コンピュータは、まず、「私は辛いカレーが好きですが、辛くておいしいカレーを自分では作れません。」と類似するデータを蓄積データ集から見つけます。たとえば、類似データとして「おいしい料理を自分で調理できません。」が見つかったとします。このとき、その類似データには、外食派の人によって書かれた、という情報が付与されていたとします(このような情報が付与されたデータを「ラベル付きデータ」と呼びます)。このラベル付きデータを判定の根拠として、コンピュータは、「私は辛いカレーが好きですが、辛くておいしいカレーを自分では作れません。」を書いた人もまた、外食派であろう、と判定します。
それでは、コンピュータは、データ間の類似度をどのように見積もるのでしょうか? よく用いられる方法は、まず、各データを高次元空間上の座標の点(つまり、ベクトル)として表す方法です。そして、点と点との距離が近いほど、データ間の類似度が高いと見なします。
2012年に、Tomas Mikolov氏(当時Google、現在Facebook)は、単語を、高次元空間上の座標の点(ベクトル)として配置する方法を提案しました。すなわち、使われ方が類似する単語どうしが近くになるように配置しました。すると、「リンゴ」―「青森」+「山形」=「サクランボ」のような等式が、おおむね成り立つことを発見しました(図3)。これが、さきほど紹介したことばの類推クイズにコンピュータが正答することの、種明かしです。
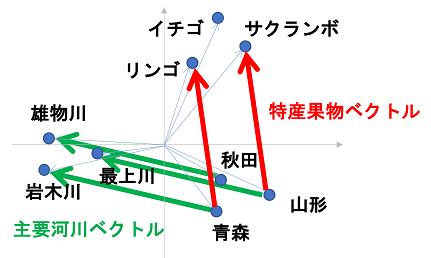
図3: 単語を高次元空間上にうまく配置すると、「特産果物ベクトル」や「主要河川ベクトル」のようなものが現れます。なお、高次元ベクトルは本来図示できません。これはイメージ図です。
しかし、試してみるとわかるように、コンピュータがことばの類推クイズに正しく答えられないことも、多くあります。私たちは、その原因の一つを、高次元による「次元の呪い」であると考えています(低次元空間では見られない不思議な現象が高次元空間で生じることがあり、「次元の呪い」と呼ばれます)。具体的には、単語を高次元ベクトルにすると、どの単語ベクトル(あるいは、複数の単語ベクトルの和や差)とも類似度が高くなりやすい特定の単語ベクトルが出現しやすくなります。すると、コンピュータは、クイズによらず特定の単語を答えとして回答する傾向が高まると考えられます。
同様のことは、蓄積された高次元のデータ集をコンピュータで類似検索する場面で、常に起こると考えられます。身近な例は、YouTubeやamazonでの「あなたへのおすすめ」です。これらのサイトが「あなたへのおすすめ」とするアイテム(動画や商品)を選ぶ基本的な仕組みは、まず、視聴履歴や購買履歴のパターンがあなたと類似するユーザを、蓄積された顧客データ集を検索して見つけます。そして、検索して見つけたユーザが高い評価を与えているアイテムを、あなたに提示します(この仕組みは「協調フィルタリング」と呼ばれます)。
いま説明した「あなたへのおすすめ」となるアイテムを選ぶ方法には欠点があります。それは、「あなたへのおすすめ」を恣意的に操作できることです。やや詳述すると、履歴パターンは高次元ベクトルとみなすことができるため、あなたを含む多くのユーザの履歴パターンと類似度が高くなるような履歴パターン持つユーザを人工的に作ることができます。このため、不正におすすめしたいアイテムに対して高い評価値を持つように、人工的なユーザを設計すると、あなたを含む多くのユーザに、そのアイテムがおすすめとして提示されやすくなります。
情報科学、データサイエンス、人工知能分野で扱う多くのデータ(テキストデータ、画像データ、音声データ、バイオ配列データなど)は高次元データであるため、上記の問題が生じていると考えられます。私たちはこの問題を解決する方法を提案してきました。研究成果は、以下のリストにあるような国際会議を中心に(あるいはジャーナル論文として)発表しています。
人工知能分野のトップ論文出版先リスト:
https://scholar.google.com/citations?view_op=top_venues&hl=ja&vq=eng_artificialintelligence
データベースと情報システム分野のトップ論文出版先リスト:
https://scholar.google.com/citations?view_op=top_venues&hl=ja&vq=eng_databasesinformationsystems

研究成果は国際会議で発表します。写真は国際会議SIGIR 2015の様子です。YAHOO!、Microsoft Research、eBay、Baiduといった企業ブースが並びます。

国際会議SISAP 2015 でポスター発表している私の様子です。